从乱到整:翻译开始之前,我们做了什么

先说一件事:翻译不只是翻译
很多人对「翻译」的理解是:找个人或者用个工具,把中文换成英文,加一份声明页和公司盖章,完事。
这个理解没有错,但只描述了整件事的一部分。
完整的翻译包含三层工序,每一层都有实质的工作量,缺任何一层,交付出来的都不是可以直接递交 USCIS 的合规文件。
第一层:版面还原(约占总工作量的 30%)
把客户上传的原始文件——PDF、Word、图片、PPT、扫描件——转化成可以被处理的、格式清晰的可编辑内容。这层在翻译开始之前完成,用户看不到,但它的质量决定了后续所有工序能做到什么水平。
第二层:文本处理(约占总工作量的 40%)
文本处理不只是把中文换成英文。它包含五个环节,缺任何一个都会影响最终质量:
- a. 术语表提取、校对与导入: EB-1A / NIW 申请的材料可能有几十到上百份文件,同一个人名、机构名、奖项名、专业名称,必须在所有文件里有且只有一个固定的英文写法。术语表在翻译开始前建立,翻译和校对过程中全程作为约束条件。
- b. 中文到英文的翻译: 这是大多数人认知里「翻译」指的那件事,也是机器工具目前最擅长的环节。它在文本处理层里约占 60%(约占总的24%) 的工作量——是占比最大的单项,但远不是全部。更关键的问题是:即便是这 60%,现有模型也存在因训练数据偏差、指令遵从度不足、上下文理解局限而导致的翻译错误,而且这类错误往往发生在对移民申请影响最大的地方。
示例一:大写金额翻译出错,合同金额失真。「壹佰肆拾肆万叁佰伍拾叁元伍角壹分」,某模型将其译为「RMB Fourteen Hundred Forty Thousand Three Hundred Fifty-Three and Fifty-One Cents Only」,实际正确译文为「RMB One Million Four Hundred Forty Thousand Three Hundred Fifty-Three and Fifty-One Cents Only」。两者相差近 13 倍。合同金额在 EB-1A / NIW 申请中是证明申请人行业影响力和领导力的核心数据,移民官看到的金额如果失真,会直接影响对申请人资质的判断。
示例二:文号缩写规则不一致,公文来源失真。「国科农技字[2018]24号」,某模型将其译为「GKNTZ [2018] No. 24」,将「技」译为「T」(来自「技术/Technology」的首字母)。但政府公文文号的缩写规则是汉字拼音首字母大写,「技」对应「J」,正确译文为「GKNJZ [2018] No. 24」。文号是公文真实性和来源机构的标识,翻译规则错误会让移民官无法核实文件来源,引发不必要的疑问。
这两类错误,人工审阅一眼就能发现,但机器不会自我纠错——这正是译文校对(d 环节)存在的原因。 - c. 译文格式调整: 译文里的列表序号是否符合英文规范(有序 / 无序);加粗、下划线、斜体是否与原文一致;表格的列宽和行高是否调整到紧凑美观;文件内嵌的图片如果含有非英文文字,图片本身也需要翻译;PPT 的文本框和图片大小、位置在翻译后需要重新调整——这一项尤其耗时。
- d. 译文校对: 检查机器直译带来的语言问题、程序处理边界导致的错误内容、术语是否按术语表正确翻译;期刊 / 杂志 / 报纸的书名需处理为斜体;学术引用中的期刊名需处理为斜体;人名与称谓、货币与数量、日期、符号、间距、地址、组织名称、文号与缩写等细节逐一核对。
- e. AI 质检 + 人工修正的闭环: 人工校对完成后,AI 再过一遍,系统性检查直译、漏译、术语错误、低级拼写和格式问题。AI 发现的问题由人工确认修正,修正后 AI 再次检查,循环直到零报错,才进入最终交付阶段。
第三层:格式交付(约占总工作量的 30%)
按统一排版规范整理所有文档,确保字体、行距、页边距、编号格式全程一致;对常见文件类型(出生证明、学位证、成绩单)使用标准模板处理,减少人工排版引入的低级错误;最后按格式完整打包——docx、pptx、图片、PDF——可以直接递交 USCIS 的完整文件包。这层的细节在第三篇文章里展开。
很多人停在「AI翻译已经很准确了,还需要翻译公司做什么」这个问题上。这个问题本身没有错,但它针对的只是文本处理层里约 60% 的那部分(把中文换成英文)——而且这 60% 里仍然存在前面两个例子那样、对移民申请有实质影响的错误。版面还原 + 格式交付合计占 60%,文本处理里翻译之外的四个环节又占另外 16%,再加上翻译本身需要校对兜底的部分,这才是翻译定价里真正在支付的内容。
这篇文章说第一层:版面还原。
版面还原是什么,为什么必须做
说一个具体场景。
客户提交了一份扫描成 PDF 的出生证明。这份 PDF 打开之后,看起来就是一张图片——里面的文字无法选中、无法复制,对翻译工具来说,它和一张白纸没有区别。
要翻译这份文件,第一步不是翻译,而是先把它变成「可以操作的文档」:识别图片里的文字,按原件的逻辑结构排列,整理成可以编辑的格式。
这就是版面还原:把各种形式的原始文件,转化为可处理的可编辑内容,同时尽可能保留原件的版面逻辑,为后续翻译和格式还原做好准备。版面还原做好了,翻译才有干净的输入。版面还原出了错,后续所有工序都要为这个错误买单。
一套 EB-1A / NIW 材料,规模有多大
先建立对规模的认知。
一个 EB-1A 或 NIW 申请人提交的材料包,通常包含 70 到 120 份文件,材料多的申请人可以达到 180 份以上。文件格式覆盖几乎所有主流文档和图片类型。
文档格式:
- PDF(含电子文字层 PDF、图片型扫描 PDF、混合型 PDF)
- Word 文档(.docx 现代格式,以及仍在流通的旧版 .doc 格式)
- Excel 表格(.xlsx 及旧版 .xls)
- PPT 演示文稿(.pptx 及旧版 .ppt)
- 上述各类文档内嵌的图片(图文混排)
- 压缩包(.zip、.rar),内含以上任意格式的组合
旧版格式(.doc、.xls、.ppt)在处理前需要先自动转换为现代格式(.docx、.xlsx、.pptx),才能进入后续流程,这是版面还原的第一步。
图片格式:.jpg、.jpeg、.jfif、.png、.bmp、.webp、.tiff、.tif、.gif、.heic——十种主流图片格式,手机拍摄、扫描仪输出、截图工具导出,来源各异,处理方式也不同。
内容性质上,同一份材料包里同时存在:带电子文字层的 PDF(可直接提取文字)、图片型扫描 PDF(需要 OCR 识别)、Word 里内嵌了图片的混合文档、只需要翻译标注区域的网页截图。没有哪一种工具能对所有情况给出同等质量的处理结果。
行业分布上,EB-1A / NIW 申请人来自医学、工程、计算机、金融、艺术、体育、法律等不同领域,每个行业的证书样式、表格结构、专业词汇都不一样。「通用」在这个场景里几乎不存在。
五类典型难题:真实文件里的挑战
版面还原遇到的难题,不是假设性的,下面是我们处理过的真实文件。
难题一:手写内容的 OCR 识别

这是一份大学成绩单里的手写「自我鉴定」。草书书写,笔画连贯,字形因人而异,OCR 识别遇到的核心问题是:相邻字符的像素区域相互叠压,工具难以判断边界,识别结果中字符错位、缺漏是常态而非例外。
我们使用百度 PaddleOCR、WPS PDF 工具、Qwen 等工具组合,针对不同文件质量和字体类型选择当次识别效果最好的方案,并持续评估新工具的识别准确率,将效果更好的工具引入流程。即便如此,手写内容仍然需要人工逐字对照原件校对——机器先产出初稿,人工逐字核对并修正,两道工序合起来才能确保原文准确无误。
原文一字之差,翻译出来的英文也会出错。手写校对是整个流程质量控制的第一道关,也是目前技术边界最清晰的地方:机器做了大量工作,但这一关还是需要人。
难题二:只翻指定区域——画框内容提取

这是一个很常见的场景:客户提交的材料是截图或者 PDF,页面上只有部分区域需要翻译——用画框、标注色块或者批注的方式指定了范围,框外的内容(固定标题、页眉页脚、印章文字、水印等)保持原样不处理。
如果方式是「把整张图片的文字全部提取」,得到的是一份混杂了大量无关内容的文字流,翻译人员还需要再花时间逐段判断哪些在框内,哪些在框外。这个判断工作是高度机械的,也很容易出错。
智通翻译的技术流程能够自动识别画框区域,只提取框内文字,框外内容自动排除。这张截图的 6 个框对应 6 段独立的文字块,分别提取、分别处理,不需要人工逐行筛选。这一能力是我们在持续处理真实客户文件的过程中迭代积累的,在行业内并不普遍。
难题三:多列密集表格的还原与校对
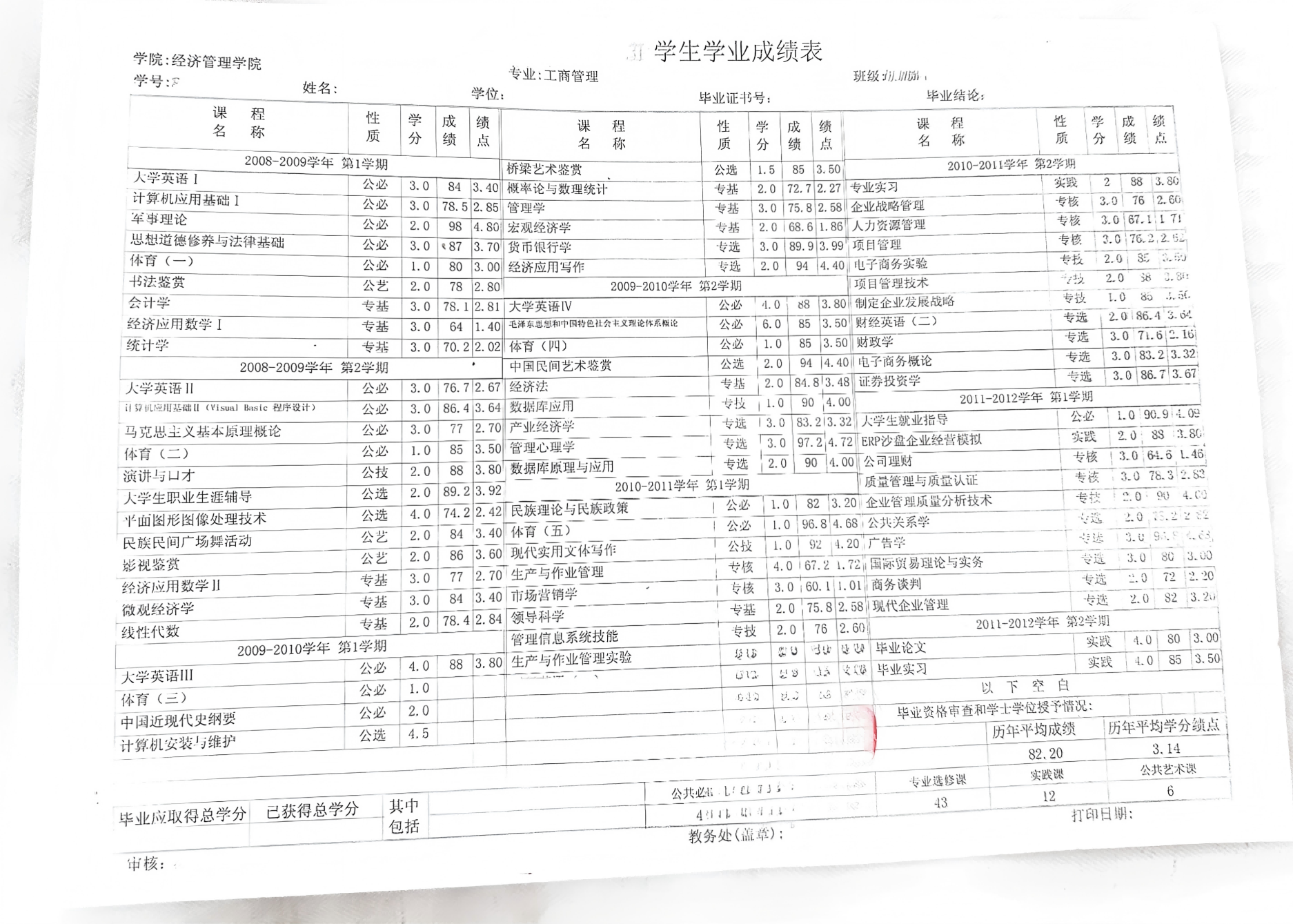
这份成绩单在一张 A4 纸上以三列并排的方式排列了多个学年的全部课程。每个单元格的文字字号很小,列与列之间的间距很窄,行与行之间几乎没有留白。
版面还原在这类表格上面临两个叠加的挑战:
第一,OCR 在密集小字的表格区域里准确率下降。相邻单元格的内容可能被合并识别,列与列之间的边框线有时无法被区分,导致内容错位——识别成功了,但放错了格子。
第二,就算 OCR 正确识别了所有文字,把识别结果还原成格式正确的可编辑表格,也需要人工逐个单元格核对:内容有没有放错位置,行列对应关系是否正确,边框线是否完整,合并单元格的位置是否正确。
现有技术处理这类密集多列表格的准确率还达不到 100%,人工校对目前仍然是必要的兜底环节。
进入文本处理阶段后,这张表格的挑战还会加大:课程名称从中文变成英文之后,长度通常增加 30% 到 80%(例如「市场营销学」变成「Principles of Marketing」),原来勉强放得下的单元格可能放不下了,出现自动换行、行高不一致、文字溢出边框等问题。此时需要重新调整列宽和行高,让整张表格在 A4 纸内紧凑、完整、可读——这是文本处理层「译文格式调整」环节的工作,在第二篇文章里展开。
难题四:含数学公式的学术论文

这是 EB-1A / NIW 申请中「学术发表」类别材料的典型文件——中文期刊论文,正文大量夹杂数学公式。
数学公式的版面还原,是几乎所有工具的共同硬伤。公式里的上下标、积分符号、矩阵括号、希腊字母,OCR 识别后往往变成乱码,或者被识别成普通文字,原有的公式结构关系完全丢失。想把识别结果「修复」回正确的公式,几乎等同于从头重新输入。
要在可编辑的 Word 文档里正确重现这些公式,需要使用 Word 内置公式编辑器逐个手工重建公式结构——这是纯人工的工作,工具在这里只能提供识别参考,没有办法代替人工输入。
翻译完成后,英文版本里的这些公式同样需要完整保留,不能用截图替代。原因很实际:截图在 Word 文档里是图片对象,无法随周围文字自动调整位置,页面缩放时会变形,打印时也可能出现分辨率问题。公式必须以可编辑的数学公式格式存在于文档里。
难题五:流程图、架构图、思维导图的版面还原
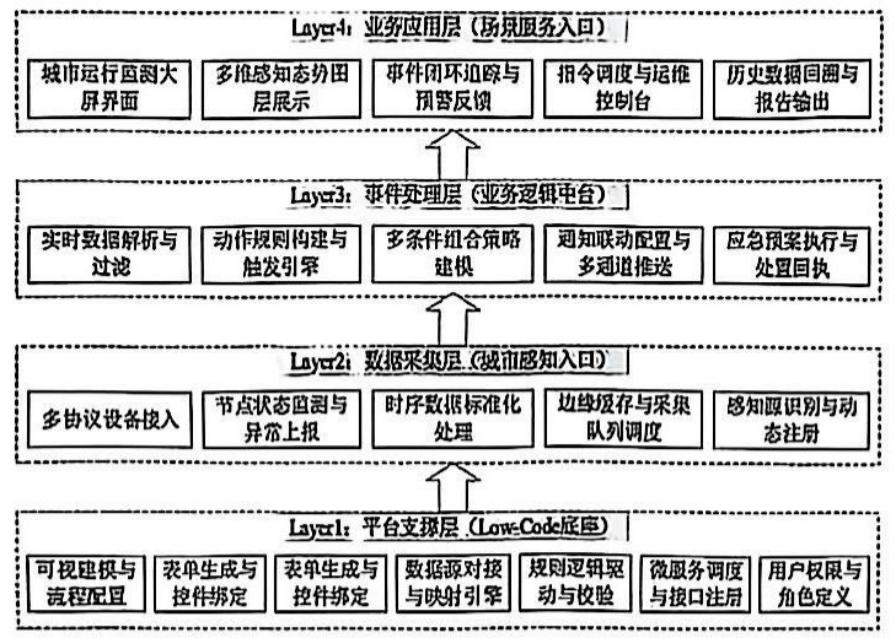
EB-1A / NIW 申请材料里,这类文件非常普遍:专利说明书里的技术架构图、研究论文里的实验流程图、项目汇报里的组织架构图、思维导图……它们的共同特点是:文字嵌入在图形里,图形有明确的层级关系和空间布局,翻译之后这些关系必须完整保留。
没有技术辅助时,这类文件的处理流程是这样的:
第一步,提取文字。 识别图中每个文字框的内容,一个框一个框地手工记录,同时记录每个框的位置关系(哪个框在哪一层、哪个框和哪个框之间有箭头)。
第二步,在画图工具里重新建图。 用 draw.io 或类似工具,按照原件的层级和位置关系,重新画出整张图的结构——先画框,再画箭头,再填入提取出来的中文文字。这一步是在「复刻」原图,目的是得到一个可编辑的图形文件。
第三步,翻译文字。 把图中每个框的中文文字翻译成英文,填回对应的框里。
第四步,重新布局。 英文文字通常比中文更长——同样的意思,英文占的字符数往往是中文的 2 到 3 倍。文字变长之后,原来排列整齐的框可能放不下,需要调整框的大小;框的大小变了之后,层与层之间的间距可能不够,需要调整图的整体尺寸;箭头的位置也随之需要重新对齐。这是一次完整的图形重布局,纯靠人工操作,没有快捷方式。
第五步,导出截图,插入 Word 文档。 图形重布局完成之后,从画图工具里导出图片,插入翻译文档对应位置,再加上翻译声明页。
整个流程,一张中等复杂度的架构图(比如上面这张四层、二十个文字框的图),从开始到插入 Word 文档,保守估计需要 2 到 4 小时。一份专利材料里可能包含 5 到 10 张这样的图,全部处理下来是相当可观的工作量。
智通翻译在这类文件上持续进行技术优化,目标是通过工具辅助减少手工重建图形结构的工作量——让机器完成尽可能多的图形识别和结构提取,人工专注于翻译内容的准确性和布局调整的最终确认,而不是从零开始画图。这类技术能力目前仍在迭代,但每一次进步都意味着这类文件的处理时间缩短,最终反映在交付效率和成本上。
版面还原的处理流程
面对 70 到 120 份、格式各异的文件,智通翻译的处理逻辑是:机器先跑,人工兜底,技术持续迭代。
格式统一化: 文件进入系统后,旧版格式(.doc、.xls、.ppt)自动转换为现代格式(.docx、.xlsx、.pptx),确保后续处理工具的兼容性。
内容性质判断与拆分: 判断文件是电子文字层、图片层还是混合型,分别走不同的处理路径。Word / Excel 内嵌的图片单独提取,PPT 的每个文本框内容独立提取并记录位置坐标,为后续翻译完成后的版面还原做准备。
OCR 识别: 图片型内容通过多工具组合识别,根据文件质量和字体类型动态选择效果最优的方案。我们持续评估新工具、新模型的识别准确率,将更优方案引入流程——技术进步意味着同等人工投入下,准确率更高,或者同等准确率下,人工校对时间更短,节省的效率最终让利于客户。
画框内容自动提取: 对于标注了需要翻译区域的文件,系统自动识别画框,只处理框内文字,跳过框外内容。
人工原文校对: 机器识别完成后,人工对照原件校对识别结果——逐字比对手写内容,逐格核对密集表格,逐公式重建数学表达式。这一步的目标是:进入翻译阶段的原文,每一个字都是准确的。
输出可编辑文档: 版面还原完成后,产出一份按原件逻辑整理好的可编辑文档:文字分段清晰,表格还原为可编辑表格,图片内文字单独列出并标注原始位置,PPT 每页文本框内容分别整理,数学公式以可编辑格式存在。这份文档是文本处理层的输入,也是最终格式交付的基础。
版面还原的成本,为什么很少被提及
因为它发生在翻译开始之前,用户拿到的是译文,看不到中间经过了什么。
但成本是真实存在的:70 到 120 份文件的格式统一化和内容提取,需要工具运行时间;图片型文件的 OCR 识别需要计算资源;手写内容、密集表格、数学公式、图形文件的人工处理,每一类都有对应的人力投入。一套完整的 EB-1A / NIW 材料包,版面还原阶段所消耗的总时间,通常与翻译本身相当,有时超过。
这是智通翻译不能与机器翻译直接比价的根本原因之一:价格里包含了用户看不见的工序,而这道工序是「可以直接递交 USCIS」与「只是翻译完了」之间最早出现的分叉。
小结
版面还原是翻译三层工序的起点,对 EB-1A / NIW 申请的材料来说,这一层的工作量尤其不可忽视——文件数量多、格式复杂、内容质量参差不齐,每一个不确定因素都需要有成熟的技术方案和人工校对来应对。
五类典型难题——手写内容的逐字校对、画框区域的精准提取、密集表格的逐格核对、数学公式的手工重建、图形文件的结构重建与重布局——没有哪一项可以完全交给工具自动完成。机器在每一类问题上都承担了尽可能多的工作量,人工在机器完成之后做准确性兜底。这个分工在可预见的将来仍然成立,区别只是机器能承担的比例会随技术进步逐渐提高。
版面还原做好之后,进入文本处理层——五个环节,翻译只是其中之一。下一篇文章展开说这些。
本文是「智通翻译的三层工序」系列第一篇。
→ 第二篇:文本处理——翻译只是五个环节之一(即将发布)
→ 第三篇:格式交付——可直接递交,是一个具体的技术标准(即将发布)
有 EB-1A 或 NIW 翻译需求?上传文件获取报价,系统自动识别字数,3 分钟出报价单,¥90/千字符起。
智通翻译(北京智通翻译有限公司)| 北京市移民及出入境服务行业协会会员单位
USCIS-Ready 认证翻译 · 15 年移民翻译行业经验