文本处理——文本翻译只是五个环节之一

上一篇说版面还原:在翻译开始之前,把客户上传的各种格式文件——扫描 PDF、手写内容、数学公式、架构图——转化成可以操作的、格式清晰的可编辑文档。这一层消耗了整个认证翻译约 30% 的工作量,用户拿到的是译文,看不见这道工序的存在。
版面还原完成之后,进入第二层:文本处理。
文本处理是三层工序里工作量最集中的一层,约占总量的 40%。更准确的说法是:这一层包含五个不能互相替代的环节,每个环节有独立的目标、独立的质量标准,缺任何一个,输出的都不是可以直接递交 USCIS 的合规译文。
五个环节,各自做什么
先把全貌放出来,再逐一展开。文本处理层的五个环节,按先后顺序排列:
1. 术语表提取、校对与导入(翻译开始前完成)
2. 中文到英文的翻译(文本处理层约 60% 的工作量)
3. 译文格式调整(与翻译同步或紧随其后)
4. 译文校对(翻译完成后)
5. AI 质检 + 人工修正的闭环(校对完成后,交付前)
这五个环节不是并行的,有严格的顺序依赖:术语表必须在翻译开始前锁定,格式调整必须等译文生成后才能进行,质检闭环必须在前四个环节全部完成后才能启动。任何一个环节出了问题,后面的工序都要为这个问题买单。
环节 1:术语表——翻译开始之前的约束条件
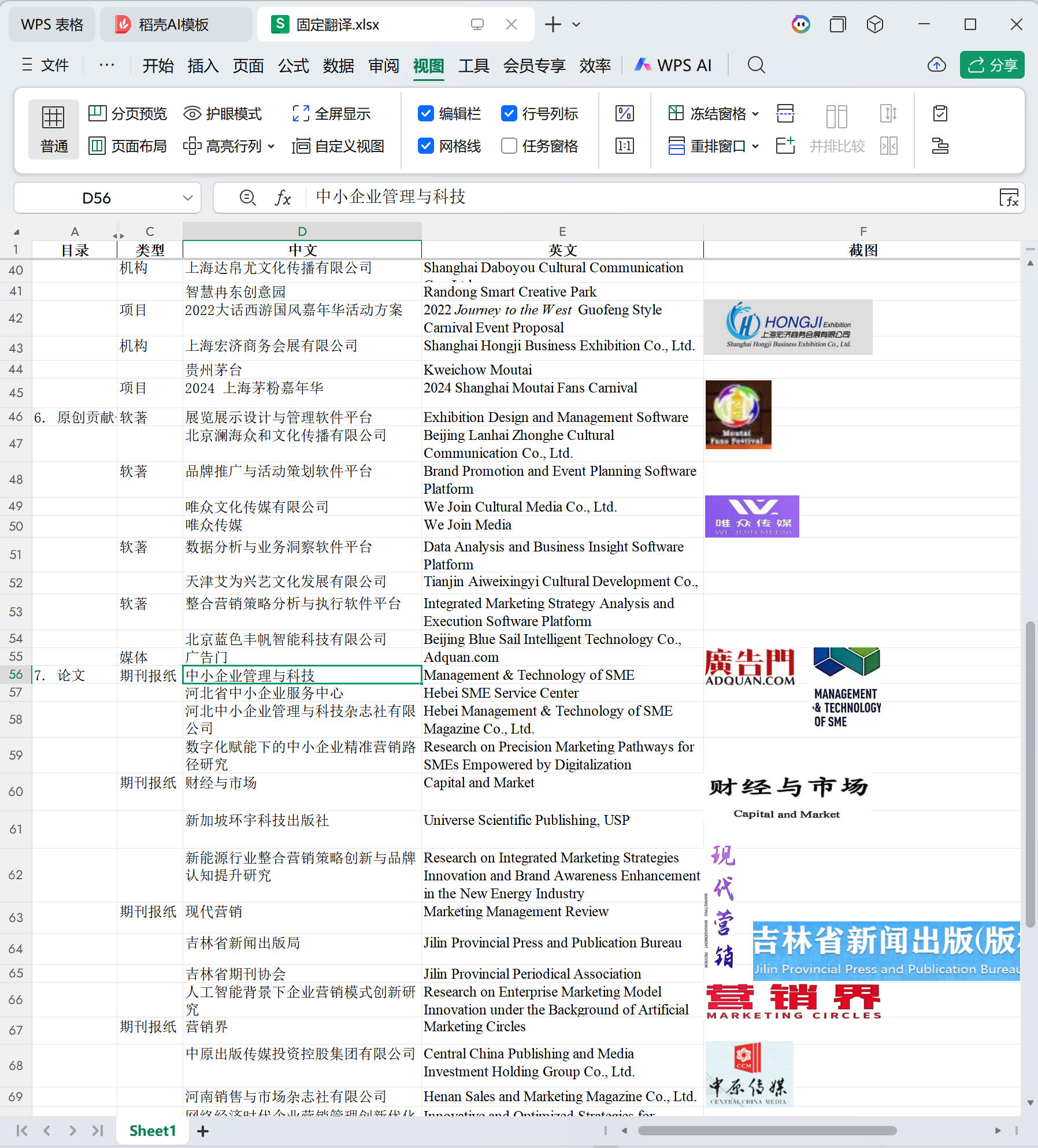
一套 EB-1A 或 NIW 材料包,通常包含 70 到 120 份文件,字符量在 10 到 25 万字之间。这些文件由不同的机构、在不同的时间出具,按照 EB-1A 和 NIW 的证据标准,通常覆盖以下类别:
期刊 / 报纸 / 书籍、媒体报道、同行评审、专利、软件著作权、课题 / 项目 / 论文、奖项、重要机构、学会与协会——九类,每一类都有自己的核心词汇。
在所有这些文件里,有一批词汇是高频出现、且必须保持统一的:申请人姓名的英文拼写、所在机构和合作单位的英文名称、奖项和称号的官方英文全称、职务与职称、专业核心术语。同一个词,在推荐信里出现,在合同里出现,在获奖证书里出现,每次必须是同一个英文写法。
如果没有术语表,会发生什么?
同一个机构名,交给不同的翻译工具,可能得到三种英文版本,取决于上下文语境和模型当次的推理路径。这三种版本散落在 70 到 120 份文件里,移民官审阅时会遇到一个问题:这是同一个机构吗?在完整性和一致性已经是审阅重点的 EB-1A / NIW 申请里,这种不一致是多余的风险,应当在翻译开始之前就消除。
术语表的提取,是一项真实的人工工作。
没有工具的情况下,这意味着把 70 到 120 份文件逐一打开,从头到尾阅读,把所有需要统一的词汇手工记录下来。25 万字的材料,这个过程本身就要花去相当的时间——这还只是「找到词」,还没有开始「确认词的正确英文」。
找到词之后,还有第二步:核查正确的英文对应。有些词汇的英文在原始文件里已经存在(例如颁奖证书上的英文奖项名、学术论文里的英文关键词),这部分可以直接引用,省去查证时间。但另一批词汇,尤其是政府机构名称、行业协会全称、地方性奖项,原始文件里没有英文,必须通过搜索引擎找到官网,核查官方英文译名。
这里的核心问题是:不能用「听起来合理」的译名,要用官方的。
「国家铁路局」是一个有代表性的例子。直译逻辑下,「国家」对应「China」或「State」,「铁路」对应「Railway」,「局」对应「Administration」或「Bureau」,组合起来会得到「China Railway Administration」「State Railway Bureau」等多种版本——但这些都不是官方译名。官方名称是「National Railway Administration of the People’s Republic of China」,这个版本只能通过查阅官网得到,无法从字面推导。
用错机构名,对申请的影响不仅是让移民官疑惑,更关键的是:如果材料中有多处引用该机构出具的证明文件,但机构名称前后不一致,审阅官可能无法确认这些文件来自同一个机构,增加补件风险。
这类需要逐一查证官方译名的词汇,在一套完整的 EB-1A / NIW 材料包里通常有数十条,覆盖各级政府主管部门、行业学会、颁奖机构。每条查证平均需要几分钟到十几分钟不等——找到官网、确认英文全称、记录来源、写入术语表。加总起来,术语表的建立往往需要6小时以上。
术语表确认完成后,导入翻译工具,作为翻译过程中的强制约束条件:凡是术语表里有的词,翻译结果必须和术语表一致,不允许模型自由发挥。
这个环节在翻译开始之前完成,看起来像是准备工作,但它是整个文本处理层的质量地基。没有它,后续所有工序的一致性都无法保证。
环节 2:翻译——最大的单项,但不是全部
这是大多数人认知里「翻译」指的那件事,文本转文本:中文进去,英文出来。在文本处理层里,这一项约占 60% 的工作量,是五个环节里最重的单项。
机器翻译在这个环节承担了主要工作。当前顶级模型对流畅书面中文的翻译能力,用于日常场景已经足够——日常沟通、一般商务文本、通用内容的处理质量普遍不差。
但 EB-1A / NIW 认证翻译不是日常场景。这是一个高度严肃、结果明确的应用场景:译文直接提交给 USCIS 移民官审阅,任何影响信息准确性的翻译错误,都可能引发 RFE 补件,延误申请进程,严重的直接影响审批结论。
在这个场景下,「够用」和「合格」之间存在一段真实的距离。
示例 1:称谓语的翻译,对移民场景来说远不够。
评审邀请邮件或企业内部通讯里,有一句极为常见的开头:「亲爱的张三同学:」
「同学」这个称谓,在国内不只限于校园场景——许多企业,尤其是科技公司和有校友文化传统的机构,日常书面通讯中普遍以「同学」作为对同事的正式称呼。无论是学术圈还是企业内部,这都是对成年专业人士的一种平等、礼貌的称谓方式。
但翻译成英文时,直接将「同学」对应「Student」,输出「Dear Student ZHANG San:」——这个结果在字面上没有错,语义也传达了,但在 EB-1A / NIW 认证翻译的专业语境里,它不合格。
正确译法是「Dear Mr. ZHANG San:」——使用正式的社交称谓(Mr. / Dr. / Prof.),姓名按英文规范大写姓氏、正常书写名字。
「Dear Student ZHANG San:」传递给移民官的信息,是对方把申请人当作在读学生在称呼;「Dear Mr. ZHANG San:」传递的是,对方在以平等的专业礼节与申请人沟通。EB-1A 要求证明的是申请人已经是行业的杰出人才,称谓语的细节同样在传递这个定位信号。
这类错误不会被自动标记——翻译结果语法正确、字面对应,工具本身无从判断它是否符合移民申请的专业标准。
示例 2:职称的英文对应词选错,专业级别被低估。
「主任医师」,如果将其译为「Director Physician」——这是把「主任」当作行政职务(主任 = Director)来处理了,而不是作为职称等级词。
实际上,「主任医师」是中国卫生专业技术职务系列的最高级别,对应的英文是「Chief Physician」。
在 EB-1A 医疗类别的申请里,「主任医师」的职称本身就是证明申请人处于领域顶端的关键证据之一。如果译文写成「Director Physician」,移民官可能无法正确理解这个职称的含义和级别,需要额外核实,甚至直接低估。「Chief Physician」和「Director Physician」,拼写只差一个词,但对申请的意义完全不同。
示例 3:学术期刊论文标题的大写规则,容易被忽略。
英文学术论文标题有固定的大写规范(Title Case):主要实词首字母大写,冠词、介词、连词小写(除非在标题开头)。
「基于深度学习的医学图像分割方法研究」,如果将其译为「Research on medical image segmentation method based on deep learning」——全部小写,违反了英文学术标题的书写规范。正确写法应为「Research on Medical Image Segmentation Method Based on Deep Learning」。
这类错误单独看似乎只是格式问题,但学术论文标题的书写规范,是移民官和 RFE(补件通知)审核中会关注到的细节之一,也是判断翻译是否专业的直观信号。更现实的问题是:如果申请人的多篇论文标题格式不一致——有的对有的错——整体上给人的印象就是翻译工作粗糙,缺乏统一的质量管控。
这类错误不会自我纠错。术语表管不到它(不属于术语),这正是译文校对(环节 4)存在的原因。
翻译环节的核心结论:机器承担了主要工作量,但机器的输出不是终点,是后续校对的起点。翻译的质量上限,由校对的严格程度决定。
环节 3:译文格式调整——翻译完成后,版面重新乱了
翻译完成的那一刻,文档里往往有一个新问题正在等着:格式错了。
不是因为翻译出了错,而是因为英文和中文在物理体积上不一样大。中文是方块字,字符数和占位空间直接对应。英文是字母语言,同样的意思用英文表达,字符数通常是中文的 2 到 3 倍。一个单元格原来装了「市场营销学」四个字,翻译后变成「Principles of Marketing」,字符数从 4 个变成了 24 个(含空格),原来合适的列宽立刻不够用了。
这个问题在以下几类文件里最为集中:
表格类文件(成绩单、合同附件、资质证书)
成绩单里的课程名称列,翻译后长度普遍增加 30% 到 80%。原来四个汉字能放下的单元格,英文版本可能需要放下十几个字母加空格,直接装不下,出现单词在单元格内强制换行——整列行高全部被撑高,相邻行视觉上对不齐,整张表格的阅读体验变得非常差。
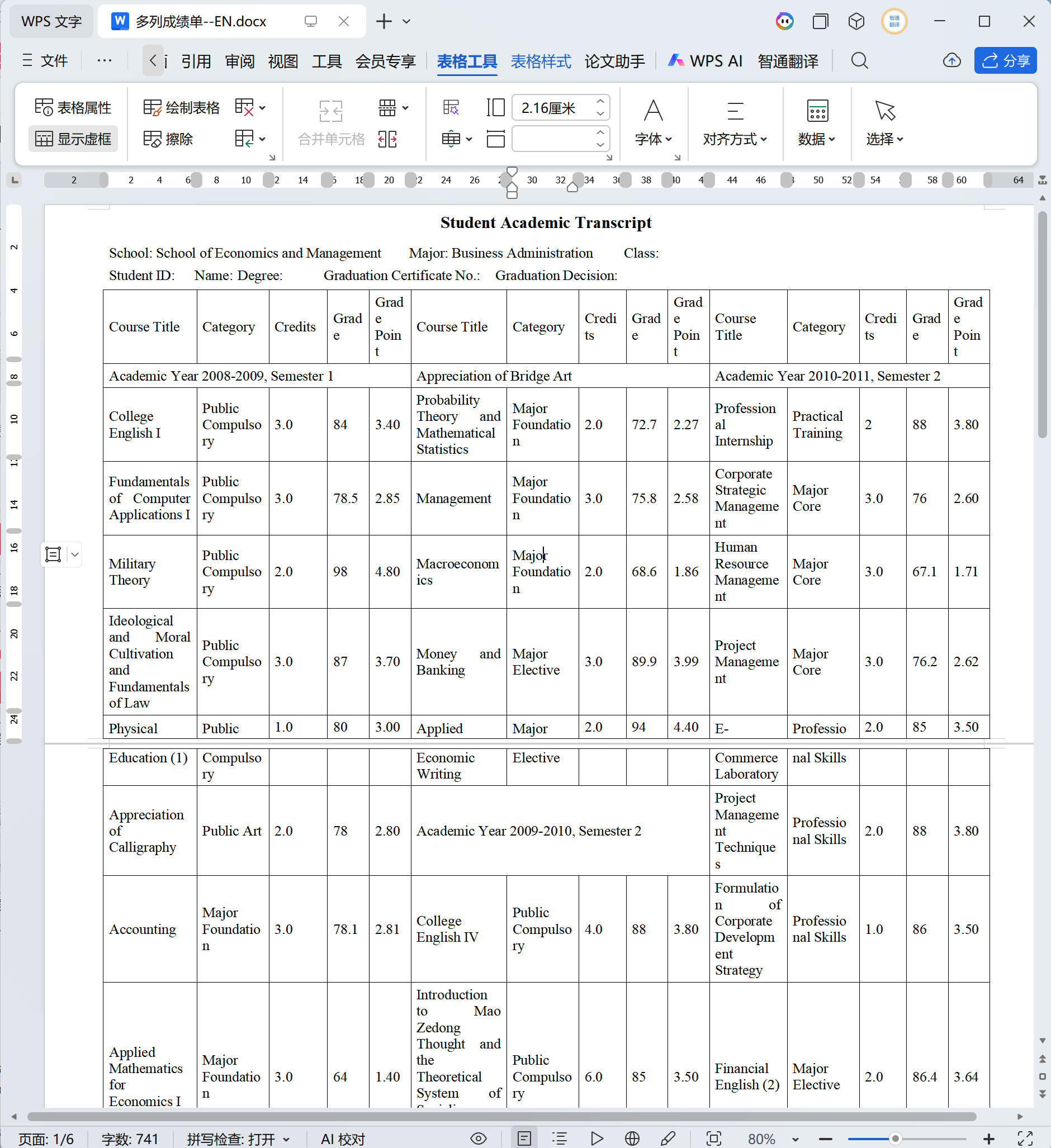
处理方式是对整张表格做系统性的版面重整:整体缩小字号、收紧单元格内边距、重新核定每列合理的宽度比例。对于相邻的两个原本独立的字段(如「姓名」和「张三」分别占两格),有时可以合并为「姓名:张三」单格,节省横向空间,阅读也更直观。调整完成后,整张表格需要在 A4 纸范围内保持紧凑、完整、可读,每一行的行高一致,不能有单词因宽度不足而换行显示。这个调整没有通用公式,每张表格的列数、字段长度、页面方向都不一样,需要逐张单独处理。
PPT 演示文稿
PPT 里的每个文本框大小和位置,在中文版本里是按中文字符量排版的。英文的信息密度比中文低——同样的意思,英文需要更多字符——翻译成英文后,原来排版整齐的幻灯片会出现几类叠加的问题:文字撑出文本框边界、字号被迫缩小到难以辨认、文字框与背景图形错位。
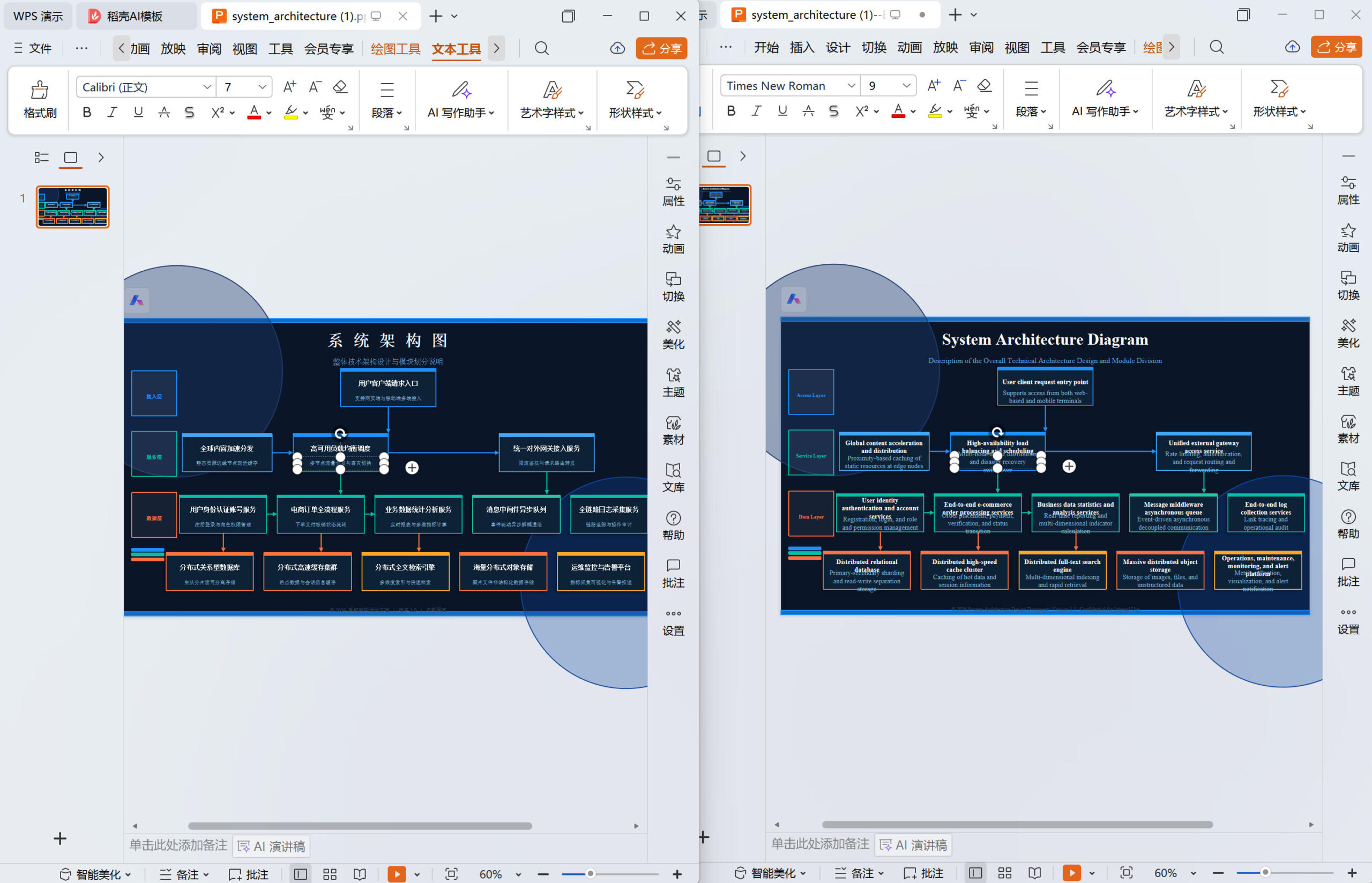
每一页都需要单独检查,逐个文本框确认内容有没有截断、字号有没有被迫缩小到影响可读性、图文的相对位置有没有错乱。一份 40 页的 PPT,每页4~10分钟,就需要2.6~6.6小时。
证据索引文件(Index)的格式统一
每一套 EB-1A / NIW 申请材料,都有一份索引文件(Index)。这是移民官拿到材料包后最先翻阅的文件:它按证据类别和逻辑顺序,列出申请人提交的所有证据及对应的文件清单,是整套材料的导航图。
索引文件的可读性,直接影响移民官对申请人材料完整性的第一印象。一份格式整洁、层级清晰、编号统一的索引,能让移民官在几分钟内建立起对申请证据体系的整体认知;反过来,格式混乱、缩进不一致、编号样式参差的索引,则会在审阅开始之前就留下不专业的印象。
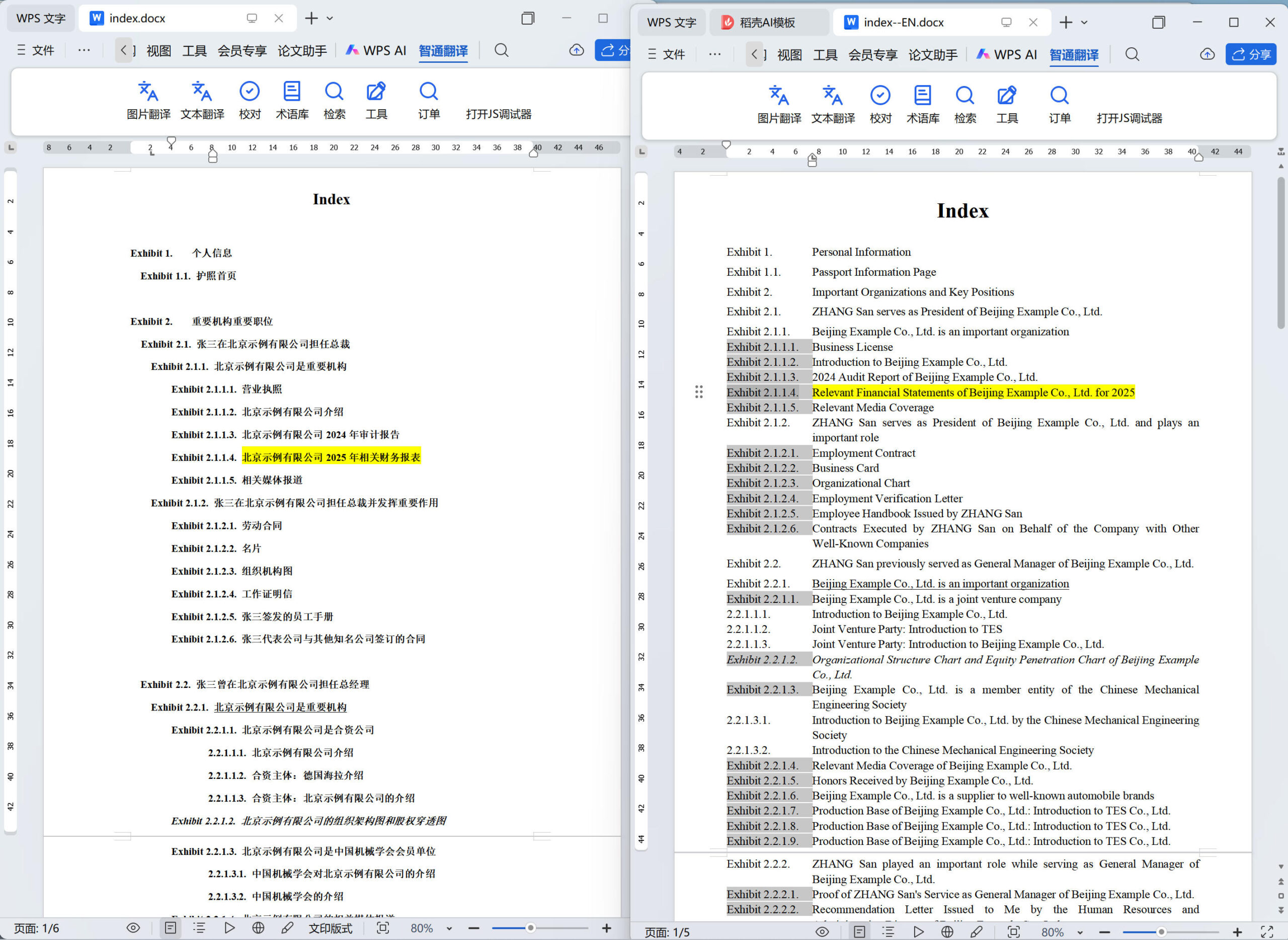
客户提供的源文档格式各不相同,有的用中文大纲格式(一、(一)、1.),有的本身就是英文但编号样式不规范,有的甚至只是简单的文字列表没有编号。智通翻译通过技术方法对这类文件进行格式统一处理:自动识别层级结构,统一编号样式,对齐各级缩进,调整首行和悬挂缩进,使整份索引文件的视觉层级与证据的逻辑结构完全对应。
索引文件之外,整套申请材料的其他文件也由系统统一排版样式:字体、行距、页边距、页眉页脚格式保持全局一致,确保移民官在翻阅任意一份文件时,看到的都是同一套视觉标准。这个全局格式统一的工作,在第三层(格式交付)里详细展开。
图片内嵌文字
Word 文档或 PDF 里内嵌的图片,如果图片本身包含中文文字(例如公司 logo 旁边的中文全称、证书上的机构名称图章),图片内的文字也需要翻译。处理方式是:提取图片内文字 → 翻译 → 在图片上覆盖英文文字层,或者在图片下方另起一行注明英文对照。两种方式各有适用场景,根据文件类型和视觉要求选择。
格式调整环节的工作量容易被低估,因为它不产出「新的内容」,只是让已有内容正确显示。但对移民官来说,一份文档是否整洁、易读、格式一致,是判断翻译质量的第一眼印象——而第一眼印象是在看具体内容之前形成的。
环节 4:译文校对——逐项核对,不放过细节
翻译完成、格式调整完成之后,进入校对环节。校对的目标不是再读一遍、大致通顺就算过。它是针对一份具体的 EB-1A / NIW 认证翻译文件,逐项确认每一个可能影响审阅结果的细节。
术语一致性核查
所有人名、机构名、奖项名、职务名,逐一比对术语表。不在术语表里的词汇,核查是否存在前后不一致的情况。这项工作在 70 到 120 份文件的体量下,不靠工具扫描是做不完的——AI 在这里承担了批量比对的工作,人工确认异常项。
斜体规范
英文学术写作里,期刊名称、杂志名称、报纸名称、书名,需要处理为斜体。「发表于《自然》杂志」,译文里「Nature」需要斜体;「引用自《经济学人》」,译文里「The Economist」需要斜体。这类规范工具几乎不会自动处理——模型关注的是把词翻准,对格式标记不敏感。校对环节逐一核查所有期刊、杂志、报纸和书名,确保斜体应用正确。
日期格式
中文日期格式是「年月日」顺序(2023年5月15日),英文日期格式是「月日年」顺序(May 15, 2023)。机器处理这类转换的准确率不稳定,存在漏转、格式混用(同一份文档里出现 05/15/2023 和 May 15, 2023 两种格式)等情况。校对逐一核查所有日期,统一格式。
货币与数量
货币金额的翻译不只是加「RMB」或「CNY」前缀,还涉及数字分位符(1,440,353.51 vs 1440353.51)、金额的文字表达是否与数字一致(票面金额文字和数字不匹配是公文里的严重问题)、单位换算是否正确(有些文件里同时涉及人民币和美元)。校对逐一核查所有金额。
政府公文文号
上一篇已经介绍了这个问题:政府公文文号的缩写规则是汉字拼音首字母大写,机器翻译经常混淆拼音首字母和英文对应词首字母。校对环节对所有出现文号的文件专项核查,逐一比对拼音缩写是否正确。
地址格式
中文地址是从大到小排列(国家→省→市→区→街道→门牌),英文地址是从小到大排列(门牌→街道→区→市→省→国家→邮编)。机器翻译时,部分模型会自动调整顺序,部分不会。校对逐一核查所有地址,确认顺序和格式符合英文规范。
漏译和错译
机器翻译存在两类低概率但影响大的错误:漏译(某一句或某一行被跳过,无声消失)和错译(翻译了,但内容与原文不符)。校对时,对关键字段——职务、金额、日期、机构名称、奖项名称——逐一回溯原文核查,不依赖「读起来顺」这个感觉判断。
校对环节是文本处理层里人力密度最高的一项。它不能被机器完整替代——机器在效率上有优势(批量扫描),但判断「这个词选得对不对」「这个格式符不符合 USCIS 的审阅习惯」,需要人工经验。这也是环节 5 的 AI 质检和环节 4 的人工校对被设计成相互补充、而不是互相替代的原因。
环节 5:AI 质检 + 人工修正的闭环
人工校对完成之后,流程没有结束。
这一环节存在,是因为一个实际情况:当一个人对着 100 份文件连续工作数小时之后,注意力是会下降的。人在疲劳状态下容易漏过的,恰恰是那种「看起来对,但其实错了」的问题——一个多余的空格,一处拼写出错的专有名词,一个应该斜体但没有斜体的期刊名。
AI 在这里承担的是系统性扫描的角色,不带疲劳地跑完所有文件:
- 漏译扫描:原文有这一段,译文里有没有对应内容
- 术语一致性扫描:同一个词在不同文件里是否有多种英文写法
- 格式规范扫描:斜体应用、列表格式、标题大写规则是否统一
- 低级错误扫描:明显的拼写错误、错误的数字格式、不该有的中文字符残留
AI 发现的每一条疑似问题,都输出给人工确认:是真正的错误,还是上下文合理的差异。人工确认是错误的,立即修正;修正完成后,AI 再次扫描,确认修正项没有引入新的问题。这个循环重复,直到 AI 报告零问题,文件才进入格式交付阶段。
「零报错」是进入下一层的门槛,不是「差不多了」。
这个闭环设计解决了一个现实问题:人工校对和 AI 扫描各有盲区。人工能判断语义和上下文,但在大体量文件里难以保持均匀的注意力;AI 能不疲劳地跑完所有文件,但无法判断「这个翻译选词对不对」这类需要背景知识的问题。两者组合,覆盖的质量控制范围才是完整的。
五个环节的关系,用一条线串起来
再看一次这五个环节之间的依赖关系,会更清楚为什么缺任何一个都会出问题:
术语表(环节 1)在翻译(环节 2)开始之前锁定,是翻译的约束条件。没有术语表,翻译结果里的一致性无法保证,后续校对需要从头查找所有不一致,工作量至少翻倍。
翻译(环节 2)完成后,格式调整(环节 3)和校对(环节 4)几乎同步推进:格式调整处理版面问题,校对处理内容问题,两者针对不同维度,不能合并。
校对(环节 4)完成后,AI 质检闭环(环节 5)做最终的系统性扫描。这一环不是「如果时间允许再做」,而是每一份交付文件的标准流程。
五个环节加起来,构成文本处理层的完整输出:一份内容准确、术语统一、格式规范、经过多轮核查的英文译文。这才是进入格式交付层的合格输入。
小结
文本处理层的 40% 工作量,分布在这五个环节里。翻译(环节 2)是最重的单项,约占这一层的 60%;但剩下的术语表、格式调整、校对、质检闭环合计占 40%,每一项都有具体的工作内容,每一项都会直接影响最终文件的质量和合规性。
「AI 翻译已经很准确了,为什么还需要这么多工序」——这个问题的答案在这里:AI 翻译处理的是环节 2 的主体部分,也就是文本处理层 60% 的工作量里的主要部分。剩下的 40%,以及环节 2 本身需要校对兜底的部分,是技术工具目前没有办法独立完成的。
更完整的成本结构是:版面还原(30%)+ 文本处理(40%)+ 格式交付(30%)。AI 直接翻译对应的是文本处理层里约 60% 的那一项——在整个认证翻译总工作量里,这个比例约为 24%。剩下的 76%,是认证翻译定价里真正在支付的内容。
下一篇说格式交付:什么是「可以直接递交 USCIS」,这是一个具体的技术标准,不是一句话的承诺。
本文是「智通翻译的三层工序」系列第二篇。
← 第一篇:版面还原——翻译开始之前,我们做了什么
→ 第三篇:格式交付——决定文件能不能直接递交
有 EB-1A 或 NIW 翻译需求?上传文件获取报价,系统自动识别字数,3 分钟出报价单。
智通翻译(北京智通翻译有限公司)| 北京市移民及出入境服务行业协会会员单位
USCIS-Ready 认证翻译 · 15 年移民行业经验